Sparse coding (Olshausen & Field, 1996) モデルの実装


- 画像のsparse coding
- 目的関数の設定
- Locally Competitive Algorithm (LCA)
- 重み行列の更新則
- Sparse coding networkの実装
- ICAとPCAによる自然画像の分析
- まとめ
- 参考文献
このノートブックでは視覚におけるSparse codingのモデル (Olshausen & Field, Nature. 1996)を解説し、Pythonによる実装を行います。コードを実行したい場合はhttps://github.com/takyamamoto/SparseCoding-OlshausenField-ModelをCloneしてsparse-coding.ipynbか、train.pyを実行してください。
画像のsparse coding
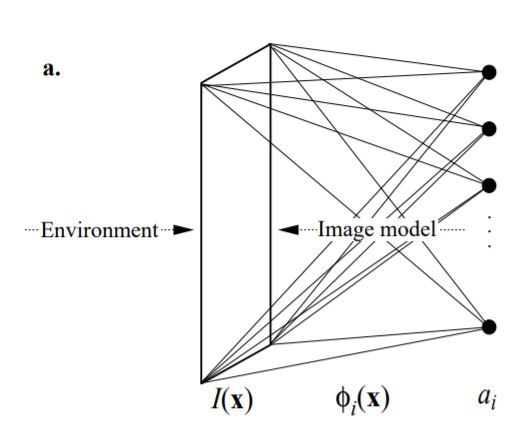
画像 $\boldsymbol{I} (\boldsymbol{x})$が基底関数(basis function) $\Phi = [\phi_i(\boldsymbol{x})]$の線形和 (係数は$\boldsymbol{r}=[r_i] $)で表されるとします。
$$ \boldsymbol{I}(\boldsymbol{x}) = \sum_i r_i \phi_i (\boldsymbol{x}) + \epsilon(\boldsymbol{x})= \Phi \boldsymbol{r} + \epsilon(\boldsymbol{x}) \tag{1} $$ただし、$\boldsymbol{x}$は画像上の座標, $\epsilon$は平均0のGaussianノイズを表します。また、$\boldsymbol{r}$は入力よりも高次の神経細胞の活動、$\Phi$は重み行列とします。
Sparse codingは、少数の基底で画像 (や目的変数)を表すことを目的とします。要は(1)式において、ほとんどが0で、一部だけ0以外の値を取るという疎 (=sparse, スカスカ)な係数$\boldsymbol{r}$を求めたい、ということです。なお、sparse codingは統計学や機械学習において一般に使用される語であることを念のために言っておきます。
目的関数の設定
Sparse codingのための目的関数(cost function) $E$は(2)式のようになります。
$$ E = \underbrace{\left\|\boldsymbol{I}-\Phi \boldsymbol{r}\right\|^2}_{\text{preserve information}} + \lambda \underbrace{\sum_i S\left(\frac{r_i}{\sigma}\right)}_{\text{sparseness of}\ r_i} \tag{2} $$ただし、$\lambda$は正則化係数、$\sigma$は定数(scaling constant)です。ここで、第一項が復元損失、第二項が罰則項 (係数が大きな値とならないようにする項)となっています。
$S(x)$としては $-\exp(-x^2), \ln(1+x^2), |x|$ などの関数が用いられます。これらの関数は原点において尖った形状をしており、解が0になりやすくなっています。描画すると以下のようになります。ただし、スケールを合わせるために $-\exp(-x^2)$には$1$を加算しました。
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-5, 5, 0.1)
plt.figure(figsize=(5,4))
plt.plot(x, np.log(1+x**2), label=r"$\ln(1+x^2)$")
plt.plot(x, np.abs(x), label=r"$|x|$")
plt.plot(x, 1-np.exp(-x**2), label=r"$1-\exp(-x^2)$")
plt.xlabel("x")
plt.ylabel(r"$S(x)$")
plt.legend()
plt.tight_layout()
plt.show()

次節からはSparse codingに基づいて最適な$\boldsymbol{r}$と$\Phi$を得る方法について説明していきます。
Locally Competitive Algorithm (LCA)
$\boldsymbol{r}$の勾配法による更新則は、目的関数 $E$の微分により次のように得られます。
$$ \begin{aligned} \frac{d \boldsymbol{r}}{dt} &= -\frac{\eta_\boldsymbol{r}}{2}\frac{\partial E}{\partial \boldsymbol{r}}\\ &=\eta_\boldsymbol{r} \cdot\left[\Phi^T (\boldsymbol{I}-\Phi\boldsymbol{r})- \frac{\lambda}{2\sigma}S'\left(\frac{r_i}{\sigma}\right)\right] \end{aligned}\tag{3} $$ただし、$\eta_{\boldsymbol{r}}$は学習率です。この式により$\boldsymbol{r}$が収束するまで最適化しますが、単なる勾配法ではなく、(Olshausen & Field, 1996)では共役勾配法 (conjugate gradient method)を用いています。しかし、共役勾配法は実装が煩雑で非効率であるため、より効率的かつ生理学的な妥当性の高い学習法として、LCA (locally competitive algorithm)が提案されています (Rozell et al., Neural Comput. 2008)。LCAは側抑制 (local competition, lateral inhibition)と閾値関数 (thresholding function)を用いる更新則です。LCAによる更新を行うRNNは通常のRNNとは異なり、コスト関数(またはエネルギー関数)を最小化する動的システムです。このような機構はHopfield networkで用いられているために、Olshausenは"the Hopfield trick"と呼んでいます。
軟判定閾値関数を用いる場合 (ISTA)
$S(x)=|x|$とした場合の閾値関数を用いる手法としてISTA(Iterative Shrinkage Thresholding Algorithm)があります。ISTAはL1-norm正則化項に対する近接勾配法で、要はLasso回帰に用いる勾配法です。
解くべき問題は(4)式で表されます。
$$ \boldsymbol{r} = \mathop{\rm arg~min}\limits_{\boldsymbol{r}}\left\{\|\boldsymbol{I}-\Phi\boldsymbol{r}\|^2_2+\lambda\|\boldsymbol{r}\|_1\right\}\tag{4} $$詳細は後述しますが、次のように更新することで解が得られます。
- $\boldsymbol{r}(0)$を要素が全て0のベクトルで初期化
- $\boldsymbol{r}_*(t+1)=\boldsymbol{r}(t)+\eta_\boldsymbol{r}\cdot \Phi^T(\boldsymbol{I}-\Phi\boldsymbol{r}(t))$
- $\boldsymbol{r}(t+1) = S_\lambda(\boldsymbol{r}_*(t+1))$
- $\boldsymbol{r}$が収束するまで2と3を繰り返す
ここで$S_\lambda(\cdot)$は軟判定閾値関数 (Soft thresholding function)と呼ばれ、(5)式で表されます。
$$ S_\lambda(y)= \begin{cases} y-\lambda & (y>\lambda)\\ 0 & (-\lambda\leq y\leq\lambda)\\ y+\lambda & (y<-\lambda) \end{cases}\tag{5} $$$S_\lambda(\cdot)$を描画すると次のようになります。
import numpy as np
import matplotlib.pyplot as plt
# thresholding function of S(x)=|x|
def soft_thresholding_func(x, lmda):
return np.maximum(x - lmda, 0) - np.maximum(-x - lmda, 0)
plt.figure(figsize=(5,4))
x = np.arange(-5, 5, 0.1)
y = soft_thresholding_func(x, 1)
plt.plot(x, x, "k--", label=r"$y=x$")
plt.plot(x, y, label=r"Soft thresholding ($\lambda=1$)")
plt.xlabel("x")
plt.ylabel(r"$S_\lambda (x)$")
plt.legend()
plt.tight_layout()
plt.show()

なお、Soft thresholding関数は次の目的関数$C$を最小化する$x$を求めることで導出できます。
$$ C=\frac{1}{2}(y-x)^2+\lambda |x| \tag{6} $$ただし、$x, y, \lambda$はスカラー値であるとします。$|x|$が微分できませんが、これは場合分けを考えることで解決します。$x\geq 0$を考えると、(6)式は
$$ C=\frac{1}{2}(y-x)^2+\lambda x = \{x-(y-\lambda)\}^2+\lambda(y-\lambda) \tag{7} $$となります。ここで、(7)式の最小値を与える$x$は場合分けをして考えると、$y-\lambda\geq0$のとき二次関数の頂点を考えて$x=y-\lambda$となります。 一方で$y-\lambda<0$のときは$x\geq0$において単調増加な関数となるので、最小となるのは$x=0$のときです。同様の議論を$x\leq0$に対しても行うことで (5)式が得られます。
Cauchy分布の閾値関数を用いる場合
次に、$S(x)=\ln(1+x^2)$を用いた場合を考えます。これはCauchy分布を$\boldsymbol{r}$の事前分布 $p(\boldsymbol{r})=\prod_i p(r_i)=\prod_i \exp\left[-\alpha \ln(1+r_i^2)\right]$としたときの負の対数事前分布 $g(\boldsymbol{r}):=-\ln p(\boldsymbol{r})=\alpha \sum_i \ln(1+r_i^2)$に対応しています。
前節と同様に次式で表される、1次元の目的関数$C$を最小にする$x$を求めます。
$$ C=(y-x)^2+\lambda \ln(1+x^2) \tag{8} $$今度は微分可能なので(8)式の勾配が0となるような$x$を求めます。
$$ \frac{\partial C}{\partial x}=-2(y-x)+\frac{2\lambda x}{1+x^2} \tag{9} $$(9)式 $=0$とおいて$x$について整理したいところですが、まずは$y$について解いてみると、
$$ y=x+\frac{\lambda x}{1+x^2} \tag{10} $$となります。後は(10)式の逆関数を求めればよいのですが、どう考えても複雑なのでWolfram alphaを使いましょう (結果)。解を整理すると(11)式のように表されます。
$$ \begin{aligned} S_\lambda(y)&=\frac{1}{3}\left[y-\frac{h_\lambda(y)}{\sqrt[3]{2}}+\frac{\sqrt[3]{2} \cdot g_\lambda(y)}{h_\lambda(y)}\right]\\ f_\lambda(y) &:= 9\lambda y - 2y^3-18y\\ g_\lambda(y) &:= 3\lambda - y^2+3\\ h_\lambda(y) &:= \left[\sqrt{f_\lambda(y)^2+4g_\lambda(y)^3}+f_\lambda(y)\right]^\frac{1}{3} \end{aligned}\tag{11} $$(11)式を実装してみると次のようになります。
# thresholding function of S(x)=ln(1+x^2)
def ln_thresholding_func(x, lmda):
f = 9*lmda*x - 2*np.power(x, 3) - 18*x
g = 3*lmda - np.square(x) + 3
h = np.cbrt(np.sqrt(np.square(f) + 4*np.power(g, 3)) + f)
two_croot = np.cbrt(2) # cubic root of two
return (1/3)*(x - h / two_croot + two_croot*g / (1e-8+h))
plt.figure(figsize=(5,4))
x = np.arange(-5, 5, 0.1)
y = ln_thresholding_func(x, 1)
plt.plot(x, x, "k--", label=r"$y=x$")
plt.plot(x, y, label=r"$\ln(1+x^2)$ thresholding ($\lambda=1$)")
plt.xlabel("x")
plt.ylabel(r"$S_\lambda (x)$")
plt.legend()
plt.tight_layout()
plt.show()

Soft thresholding 関数を緩やかにしたような形状であることが分かります。しかし、これをそのまま用いてもスパースな表現は得られませんでした (ハイパーパラメータの調整不足かもしれませんが)。そこで、(Mayo et al., arXiv. 2020)で提案されているCauchy thresholding関数を用いてみましょう。
Cauchy thresholding関数は次式で表されます。
$$ S_\lambda(y)= \begin{cases} \dfrac{1}{2}\left(y+\sqrt{y^2-4\lambda}\right) & (y>2\lambda)\\ 0 & (-2\lambda\leq y\leq 2\lambda)\\ \dfrac{1}{2}\left(y-\sqrt{y^2-4\lambda}\right) & (y<-2\lambda) \end{cases}\tag{12} $$実装は次のようになります。
def cauchy_thresholding_func(x, lmda):
f = 0.5*(x + np.sqrt(np.maximum(x**2 - lmda,0)))
g = 0.5*(x - np.sqrt(np.maximum(x**2 - lmda,0)))
return f*(x>=lmda) + g*(x<=-lmda)
plt.figure(figsize=(5,4))
x = np.arange(-5, 5, 0.1)
ln_thresholding_func
y = cauchy_thresholding_func(x, 1)
plt.plot(x, x, "k--", label=r"$y=x$")
plt.plot(x, y, label=r"Cauchy thresholding ($\lambda=1$)")
plt.xlabel("x")
plt.ylabel(r"$S_\lambda (x)$")
plt.legend()
plt.tight_layout()
plt.show()

硬判定閾値関数 (hard thresholding function)に似た形状をしていることが分かります。
import numpy as np
import matplotlib.pyplot as plt
import network
from tqdm.notebook import tqdm
import scipy.io as sio
np.random.seed(0)
画像データの読み込み
データはhttp://www.rctn.org/bruno/sparsenet/からダウンロードできます。MATLABコードもダウンロードできますが、手元では動かすことができませんでした。IMAGES.matには白色化された10枚の自然画像が記録されています。画像の描画などは『Predictive coding (Rao & Ballard, 1999) モデルの実装』を参照してください。
# datasets from http://www.rctn.org/bruno/sparsenet/
mat_images = sio.loadmat('datasets/IMAGES.mat')
imgs = mat_images['IMAGES']
class OlshausenField1996Model:
def __init__(self, num_inputs, num_units, batch_size,
lr_r=1e-2, lr_Phi=1e-2, lmda=5e-3):
self.lr_r = lr_r # learning rate of r
self.lr_Phi = lr_Phi # learning rate of Phi
self.lmda = lmda # regularization parameter
self.num_inputs = num_inputs
self.num_units = num_units
self.batch_size = batch_size
# Weights
Phi = np.random.randn(self.num_inputs, self.num_units).astype(np.float32)
self.Phi = Phi * np.sqrt(1/self.num_units)
# activity of neurons
self.r = np.zeros((self.batch_size, self.num_units))
def initialize_states(self):
self.r = np.zeros((self.batch_size, self.num_units))
def normalize_rows(self):
self.Phi = self.Phi / np.maximum(np.linalg.norm(self.Phi, ord=2, axis=0, keepdims=True), 1e-8)
# thresholding function of S(x)=|x|
def soft_thresholding_func(self, x, lmda):
return np.maximum(x - lmda, 0) - np.maximum(-x - lmda, 0)
# thresholding function of S(x)=ln(1+x^2)
def ln_thresholding_func(self, x, lmda):
f = 9*lmda*x - 2*np.power(x, 3) - 18*x
g = 3*lmda - np.square(x) + 3
h = np.cbrt(np.sqrt(np.square(f) + 4*np.power(g, 3)) + f)
two_croot = np.cbrt(2) # cubic root of two
return (1/3)*(x - h / two_croot + two_croot*g / (1e-8+h))
# thresholding function https://arxiv.org/abs/2003.12507
def cauchy_thresholding_func(self, x, lmda):
f = 0.5*(x + np.sqrt(np.maximum(x**2 - lmda,0)))
g = 0.5*(x - np.sqrt(np.maximum(x**2 - lmda,0)))
return f*(x>=lmda) + g*(x<=-lmda)
def calculate_total_error(self, error):
recon_error = np.mean(error**2)
sparsity_r = self.lmda*np.mean(np.abs(self.r))
return recon_error + sparsity_r
def __call__(self, inputs, training=True):
# Updates
error = inputs - self.r @ self.Phi.T
r = self.r + self.lr_r * error @ self.Phi
self.r = self.soft_thresholding_func(r, self.lmda)
#self.r = self.cauchy_thresholding_func(r, self.lmda)
if training:
error = inputs - self.r @ self.Phi.T
dPhi = error.T @ self.r
self.Phi += self.lr_Phi * dPhi
return error, self.r
# Simulation constants
H, W, num_images = imgs.shape
num_iter = 500 # number of iterations
nt_max = 1000 # Maximum number of simulation time
batch_size = 250 # Batch size
sz = 16 # image patch size
num_units = 100 # number of neurons (units)
eps = 1e-2 # small value which determines convergence
error_list = [] # List to save errors
# Define model
model = OlshausenField1996Model(num_inputs=sz**2, num_units=num_units,
batch_size=batch_size)
# Run simulation
for iter_ in tqdm(range(num_iter)):
# Get the coordinates of the upper left corner of clopping image randomly.
beginx = np.random.randint(0, W-sz, batch_size)
beginy = np.random.randint(0, H-sz, batch_size)
inputs_list = []
# Get images randomly
for i in range(batch_size):
idx = np.random.randint(0, num_images)
img = imgs[:, :, idx]
clop = img[beginy[i]:beginy[i]+sz, beginx[i]:beginx[i]+sz].flatten()
inputs_list.append(clop - np.mean(clop))
inputs = np.array(inputs_list) # Input image patches
model.initialize_states() # Reset states
model.normalize_rows() # Normalize weights
# Input an image patch until latent variables are converged
r_tm1 = model.r # set previous r (t minus 1)
for t in range(nt_max):
# Update r without update weights
error, r = model(inputs, training=False)
dr = r - r_tm1
# Compute norm of r
dr_norm = np.linalg.norm(dr, ord=2) / (eps + np.linalg.norm(r_tm1, ord=2))
r_tm1 = r # update r_tm1
# Check convergence of r, then update weights
if dr_norm < eps:
error, r = model(inputs, training=True)
break
# If failure to convergence, break and print error
if t >= nt_max-2:
print("Error at patch:", iter_)
print(dr_norm)
break
error_list.append(model.calculate_total_error(error)) # Append errors
# Print moving average error
if iter_ % 100 == 99:
print("iter: "+str(iter_+1)+"/"+str(num_iter)+", Moving error:",
np.mean(error_list[iter_-99:iter_]))
訓練中の損失の変化を描画してみましょう。損失が低下し、学習が進行したことが分かります。
# Plot error
plt.figure(figsize=(5, 3))
plt.ylabel("Error")
plt.xlabel("Iterations")
plt.plot(np.arange(len(error_list)), np.array(error_list))
plt.tight_layout()
plt.show()

# Plot Receptive fields
fig = plt.figure(figsize=(6, 6))
plt.subplots_adjust(hspace=0.1, wspace=0.1)
for i in tqdm(range(num_units)):
plt.subplot(10, 10, i+1)
plt.imshow(np.reshape(model.Phi[:, i], (sz, sz)), cmap="gray")
plt.axis("off")
fig.suptitle("Receptive fields", fontsize=20)
plt.subplots_adjust(top=0.9)
plt.show()

白色がON領域(興奮)、黒色がOFF領域(抑制)を表します。Gaborフィルタ様の局所受容野が得られており、これは一次視覚野(V1)における単純型細胞(simple cells)の受容野に類似しています。
なお、cauchy_thresholding_funcを用い、lmda=1e-3とした結果は次図のようになりました。

ICAとPCAによる自然画像の分析
参考までに自然画像に対してICAとPCAを実行してみます。ICAを実行することはSparse codingを行うことと同じであり、結果としてGaborフィルタ様の局所受容野が得られます。一方で、PCAを実行しても広域的な受容野しか得られません (Sanger TD, 1989)。
ライブラリのimport
sklearn.decompositionを持ちます。
from sklearn.decomposition import FastICA, PCA
mat_images_raw = sio.loadmat('datasets/IMAGES_RAW.mat')
imgs_raw = mat_images_raw['IMAGESr']
# Simulation constants
H, W, num_images = imgs_raw.shape
num_patches = 15000
patchs_list = []
w, h = 16, 16 # patch size
# generate patches
for i in tqdm(range(num_patches)):
i = np.random.randint(0, num_images)
# Get the coordinates of the upper left corner of clopping image randomly.
beginx = np.random.randint(0, W-w-1)
beginy = np.random.randint(0, H-h-1)
img_clopped = imgs_raw[beginy:beginy+h, beginx:beginx+w, i]
patchs_list.append(img_clopped.flatten())
patches = np.array(patchs_list)
# perform ICA
n_comp = 100
ica = FastICA(n_components=n_comp)
ica.fit(patches)
ica_filters = ica.components_
# plot filters
plt.figure(figsize=(6,6))
plt.subplots_adjust(hspace=0.1, wspace=0.1)
for i in tqdm(range(n_comp)):
plt.subplot(10, 10, i+1)
plt.imshow(np.reshape(ica_filters[i], (w, h)), cmap="gray")
plt.axis("off")
plt.suptitle("ICA", fontsize=20)
plt.subplots_adjust(top=0.9)
plt.show()

他にはK-means法を用いることでもGaborフィルタを得ることはできます。
# perform PCA
pca = PCA(n_components=n_comp)
pca.fit(patches)
pca_filters = pca.components_
# plot filters
plt.figure(figsize=(6,6))
plt.subplots_adjust(hspace=0.1, wspace=0.1)
for i in tqdm(range(n_comp)):
plt.subplot(10, 10, i+1)
plt.imshow(np.reshape(pca_filters[i], (w, h)), cmap="gray")
plt.axis("off")
plt.suptitle("PCA", fontsize=20)
plt.subplots_adjust(top=0.9)
plt.show()

参考文献
論文
- Olshausen BA, Field DJ. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature. 1996;381(6583):607–609. Data and Code, pdf
- Olshausen BA. Principles of Image Representation in Visual Cortex. The Visual Neurosciences. 2002.
- Rozell CJ, Johnson DH, Baraniuk RG, Olshausen BA. Sparse coding via thresholding and local competition in neural circuits. Neural Comput. 2008;20(10):2526‐2563.
- Mayo P, Holmes R, Achim A. Iterative Cauchy Thresholding: Regularisation with a heavy-tailed prior. arXiv. 2020.
- Paiton DM. Analysis and applications of the Locally Competitive Algorithm. UC Berkeley. 2019.
GitHubで確認した他の実装例
Olshausen先生の講義
- Bruno Olshausen: “Sparse coding in brains and machines”(Stanford talks), Slide
- https://redwood.berkeley.edu/wp-content/uploads/2018/08/sparse-coding-LCA.pdf